Data Preparation
Few data sets in practice are perfect therefore we need preparation steps after importing data.
Converting string to numeric
There are times when pandas import a numeric variable as string when there are non-numeric rows in the dataset. To solve this problem we can use to_numeric function. Take a look at the telco dataset.
import pandas as pd
import numpy as np
telco = pd.read_csv('D:\\teaching\\telco.csv')
Let's see the data types of our imported variables:
telco.dtypes
customerID object gender object Senior int64 Partner object Dependents object tenure int64 PhoneService object MultipleLines object InternetService object OnlineSecurity object OnlineBackup object DeviceProtection object TechSupport object StreamingTV object StreamingMovies object Contract object PaperlessBilling object PaymentMethod object MonthlyCharges float64 TotalCharges object Churn object dtype: object
As seen from above variable TotalCharges is imported as object whereas it ought to be float. We have two options to fix this: one, convert string to float and when there is an unconvertable string, record it as NaN. Second option is to further process this dataset and convert NaN's to zero.
telco.TotalCharges = pd.to_numeric(telco.TotalCharges, errors='coerce').astype(np.float64)
errors='coerce' option tells to_numeric function convert unconvertable strings to NaN. If we want to get rid of NaN's we can delete those rows:
telco.dropna(TotalCharges)
or convert them to zero from the very beginning with the to_numeric function:
telco.TotalCharges = pd.to_numeric(telco.TotalCharges, errors='coerce').fillna(0).astype(np.float64)
Dealing with dates
Take a look at the waltham dataset.
waltham.dtypes
SellingPrice float64 Beds float64 Baths float64 BuildingSqFt float64 LotSqFt float64 YearBuilt float64 ZipCode float64 DateSold object ElementarySchool float64 Heat float64 CentralAC float64 FinishedBasement float64 Parking float64 Rooms float64 BldgGrade float64 BldgCondition float64 dtype: object
As seen above variable DateSold is an object, i.e. string. To convert this to a datetime object we will use DatetimeIndex function from pandas.
import pandas as pd
waltham.DateSold = pd.DatetimeIndex(waltham.DateSold)
Let's see if our variable type has changed:
waltham.dtypes
SellingPrice float64 Beds float64 Baths float64 BuildingSqFt float64 LotSqFt float64 YearBuilt float64 ZipCode float64 DateSold datetime64[ns] ElementarySchool float64 Heat float64 CentralAC float64 FinishedBasement float64 Parking float64 Rooms float64 BldgGrade float64 BldgCondition float64 dtype: object
Changing dtypes
There will be times when you may want to change the data type of a dataframe column for various reasons. For example you may have a dataframe like below and you want to change the dtype from float to int16 for a more efficient use of memory.
| A | B |
|---|---|
| 1.0 | 1.0 |
| 2.0 | 4.0 |
| 3.0 | 9.0 |
| 4.0 | 16.0 |
| 5.0 | 25.0 |

| A | B |
|---|---|
| 1 | 1 |
| 2 | 4 |
| 3 | 9 |
| 4 | 16 |
| 5 | 25 |
To change the dtype of the whole dataframe to one dtype:
df = df.astype('int16')
What if we instead want to change the data type of column 'A' instead?
df.A = df.A.astype('int16')
Changing index
pandas dataframes by default are created with indices and they are very important in various data operations such as joins and there will be times we need to modify them. For example, take a look at a simple dataframe below. Column to the left of column A is the index.
A B 0 1 2 1 2 4 2 3 9 3 4 16 4 5 25
Let's say we want to use column A as the index instead. To do that:
df = df.set_index('A')
B A 1 2 2 4 3 9 4 16 5 25
If we want to get rid of this index and create a new one all we have to do is assign an array or series to it:
df.index = np.arange(0,10,2)
B 0 2 2 4 4 9 6 16 8 25
Modifying rows on conditional logic
Python offers powerful tools to modify data based on conditional logic. For example take a look at the table below.
| day | time | measure |
| 307 | 2210 | 37.71 |
| 307 | 2220 | 37.78 |
| 307 | 2230 | 37.82 |
| 307 | 2240 | 37.76 |
| 307 | 2250 | 37.81 |
| 307 | 2300 | 37.84 |
| 307 | 2310 | 38.01 |
| 307 | 2320 | 38.1 |
| 307 | 2330 | 38.15 |
| 307 | 2340 | 37.92 |
| 307 | 2350 | 37.64 |
| 308 | 0 | 37.7 |
| 308 | 10 | 37.46 |
| 308 | 20 | 37.41 |
| 308 | 30 | 37.46 |
| 308 | 40 | 37.56 |
| 308 | 50 | 37.55 |
| 308 | 100 | 37.75 |
| 308 | 110 | 37.76 |
| 308 | 120 | 37.73 |
| 308 | 130 | 37.77 |
| 308 | 140 | 38.01 |
| 308 | 150 | 38.04 |
| 308 | 200 | 38.07 |
Let's say we want to plot the change of measure with time but time becomes zero with the change of day. To fix this we need to add 2400 to time when the day is 308. To do this
beaver.loc[beaver.day == 308,'time'] = beaver.loc[beaver.day == 308,'time'] + 2400
Example: Preparing Netflix Data
This is a challenging example with millions of rows. You can download the dataset from here.
Here's what the first part of dataset (combined_data_1.txt) looks like:
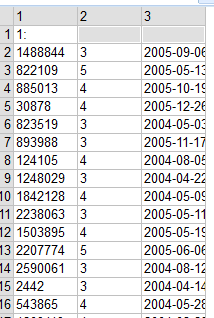
Column 1 is CustomerID, column 2 is Rating and column 3 is Date. We are missing movie that's being rated! It's actually here: take a look at row 1: movie #1. Data is set up such that each movie no separates data into subsets. We'd better to create a new row and assign movie numbers there.
Let's first import our data into a pandas dataframe:
net1 = pd.read_csv('D:\\teaching\\netflix\\combined_data_1.txt', skiprows=1, header=None, names=['CustomerID','Rate','Date'])

Lrrr
Senior blog writer
Lrrr, ruler of the planet Omicron Persei 8, is a middle-aged Omicronian man with a bad temper and soft spots for the conquering of planets and 20th century television.
Popular Posts

Space The Final Frontier
02 Hours ago

The Amazing Hubble
02 Hours ago

Astronomy Or Astrology
02 Hours ago

Asteroids telescope
02 Hours ago

Leave a Comment